
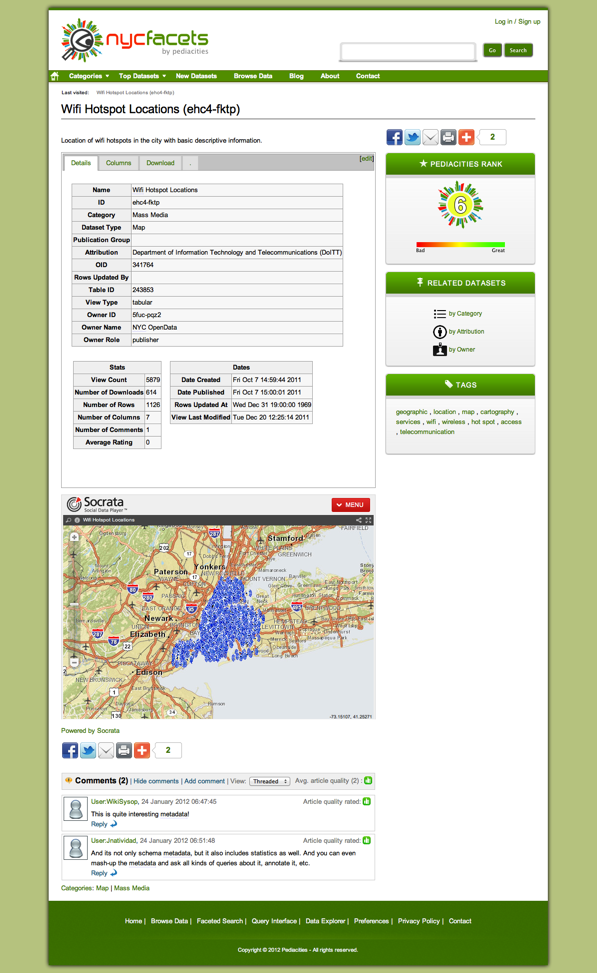
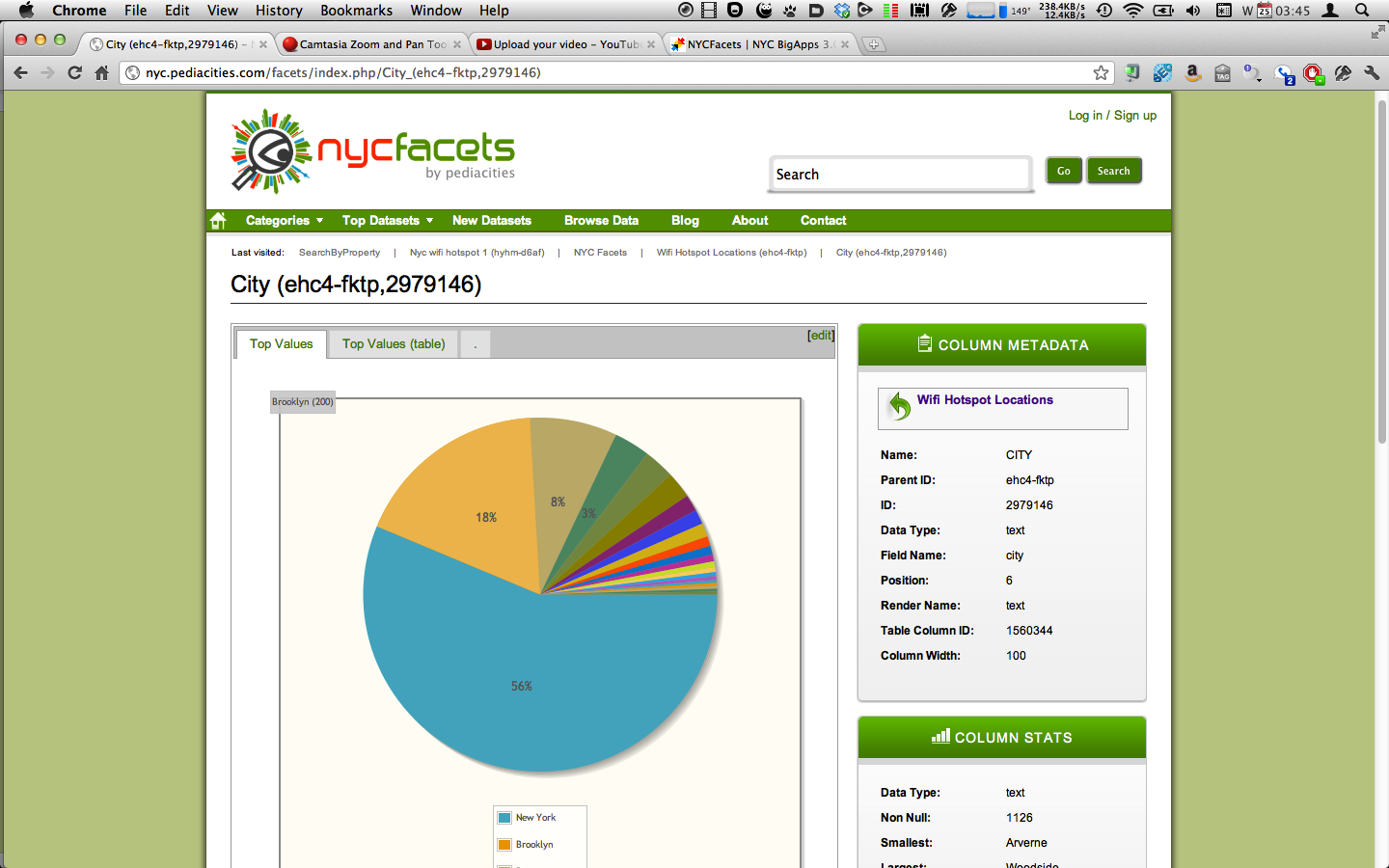

There is a tremendous amount of data in NYC Open Data. How do you make sense of it? How do you ensure the quality of the data? How do you slice and dice it? How do you make it available not only to developers but to businesses, city visitors and citizens alike? How do you make intelligent, federated queries? What happens when NYC exposes all its data and exponentially increase the amount of data in it? How do you mash it up with other data sources, both public and private, on the web and behind the firewall? With our "crowdknowing" approach - metadata + derived extrametadata (using semantics, statistics and the crowd), we aim to create an open-data mash-up portal on steroids that can collaborate structured and unstructured information. We aim to create an Open City Metadata Exchange using open standards - creating a hyperlocal "River of Data", whereby data innovators can build interchangeable solutions using their preferred technology stack while minimizing data balkanization. On the riverbanks of this River of Data, we aim to help NYC achieve its vision - to become the premier Digital City of the Future!
NYCFacets

Updates

Leave feedback in the comments!
Log in or sign up for Devpost to join the conversation.